
In a previous post, I've described how we can monitor our spring boot application(s) metrics over time, in a time-series fashion, using the elastic stack. In this post we'll discuss how to achieve the same goal, using another open source stack: Prometheus and Grafana.
Prometheus
Prometheus is a simple, effective open-source monitoring system. It has become particularly successful because of its intuitive simplicity. It doesn’t try to do anything fancy. It provides a data store, data scrapers, an alerting mechanism and a very simple user interface.
The data scrapers use a pull model. I.e. Prometheus has to pull metrics from individual machines and services. This does mean that we have to plan to provide metrics endpoints in our custom services (there are automatic scrapers for a range of common out-of-the-box technologies) in a text-based data format that Prometheus understands. Once Prometheus has the data, you can analyse it, create alerts or expose certain stats to a dashboard.
Prometheus and Spring Boot
First off, we need to add the following dependencies to our Spring Boot application:
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_spring_boot</artifactId>
<version>0.1.0</version>
</dependency>
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_hotspot</artifactId>
<version>0.1.0</version>
</dependency>
The simpleclient_spring_boot dependency provides the @EnablePrometheusEndpoint annotation. Adding it to a @configuration class, creates a HTTP endpoint accessible via /prometheus that exposes all registered (actuator) metrics in a Prometheus data format.
# HELP mem_free mem_free
# TYPE mem_free gauge
mem_free 205210.0
# HELP processors processors
# TYPE processors gauge
processors 8.0
# HELP instance_uptime instance_uptime
# TYPE instance_uptime gauge
instance_uptime 3443651.0
# HELP uptime uptime
# TYPE uptime gauge
uptime 3431906.0
# HELP systemload_average systemload_average
# TYPE systemload_average gauge
systemload_average 2.0673828125
Once our exporter is running, let’s go to configure Prometheus by modifying the prometheus.yml file.
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['PROM_IP:9090']
- job_name: 'spring-boot'
metrics_path: '/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['App_IP:8080']
On the above configuration, Prometheus scrap 2 endpoints, the spring boot /prometheus endpoint, which contains Spring boot metrics, and prometheus own metrics. Once done, we can explore our saved metrics on prometheus:
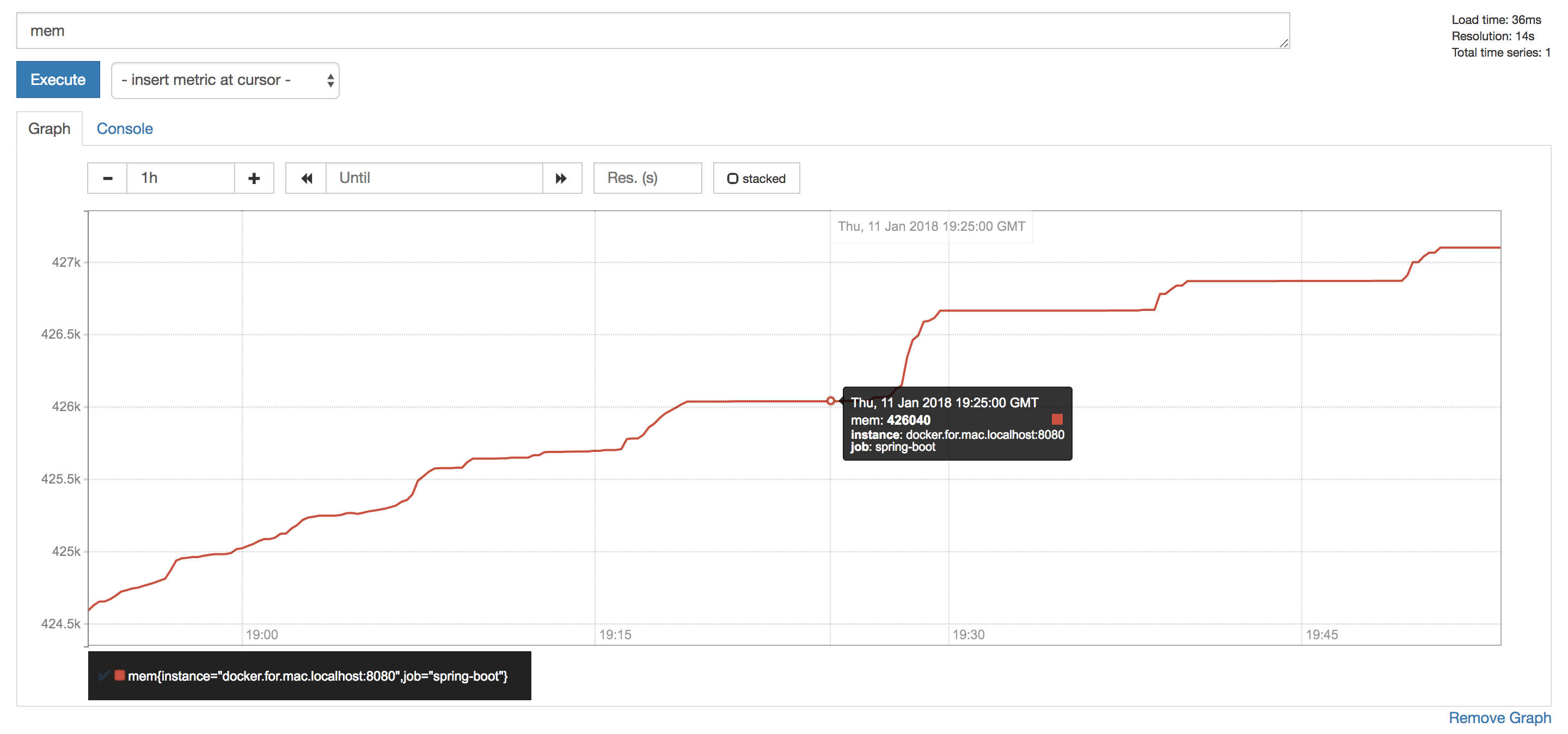
Grafana
We all agree that Prometheus UI isn’t going to win any design awards, but it still functional and great for debugging during development. For full-time dashboards, We'd use one of the many dashboarding tools that support Prometheus such as Grafana. It means that Prometheus can concentrate on what it does best, monitoring.
The integration of Prometheus and Grafana is so seamless, once done, we can start building our super awesome dashboard. Below is an example:
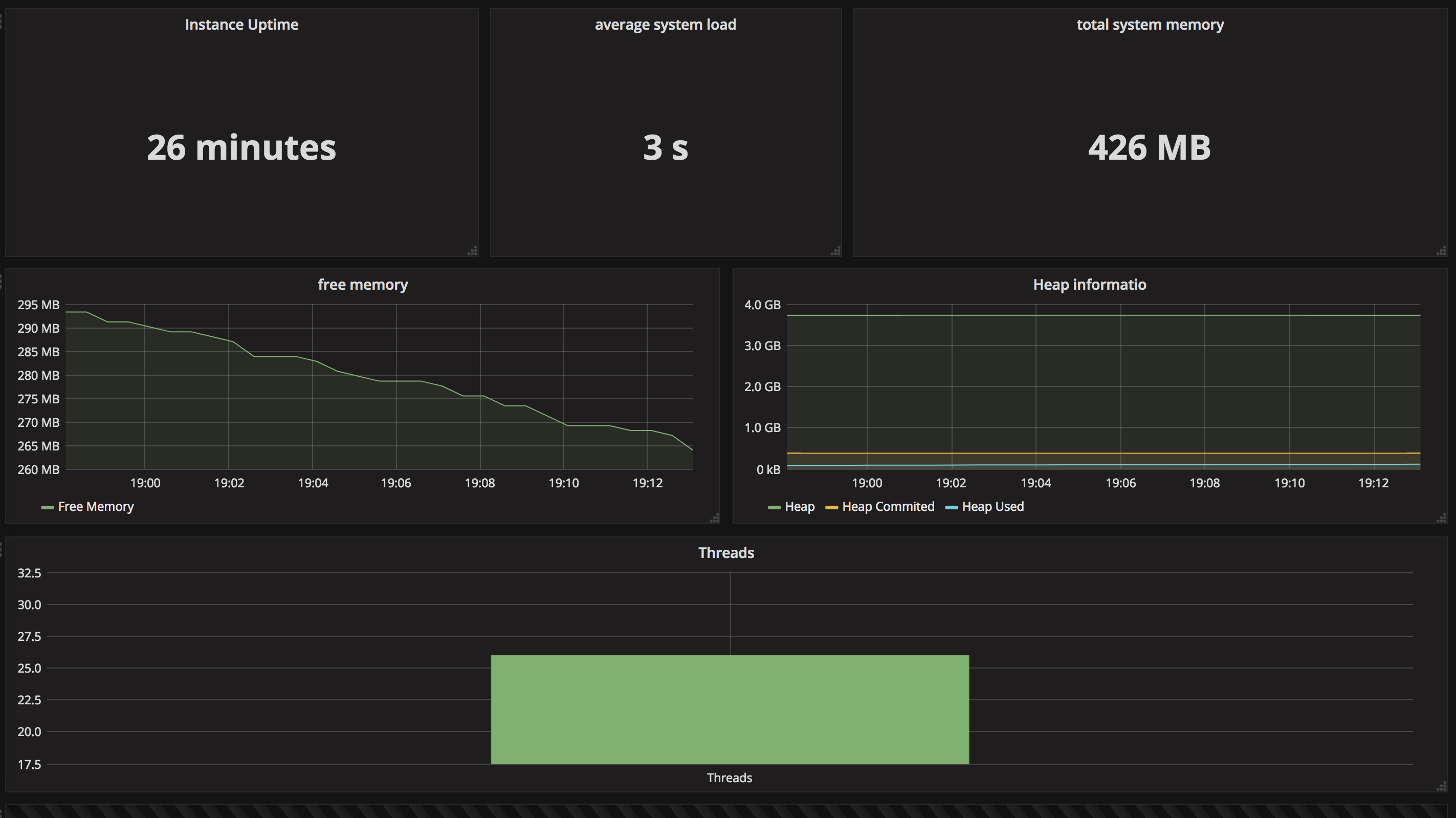
and Voila! a minimalist example is available on github.