kubernetes Building Production-Grade RAG Systems: Kubernetes, Autoscaling & LLMs We finally got first drop of snow this week in Stockholm. The
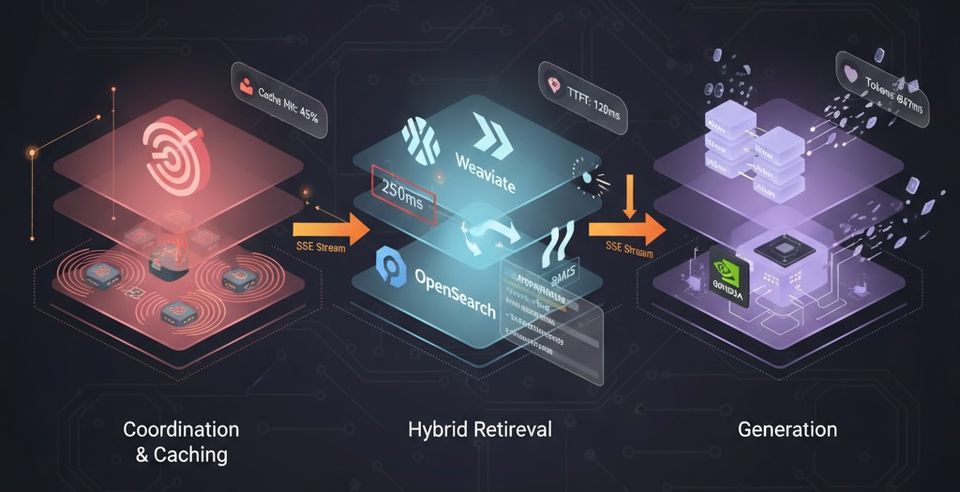
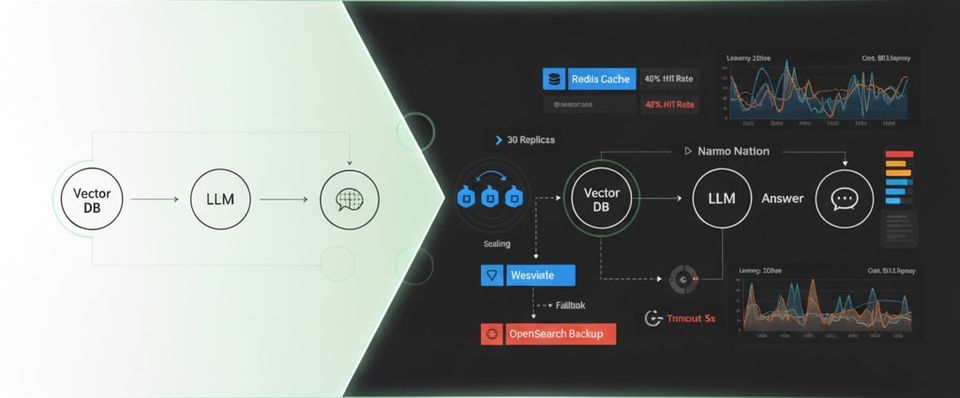
Java Building Production-Grade RAG Systems: Architecture Deep Dive In the first part, we explored the production challenges of RAG systems:
Java Building Production-Grade RAG Systems: Understanding the Problem Space I've been quiet on this blog for a while now. Truth is,
Java A look into Deep Java Library! When you think about building machine learning apps, Java is not the
kubernetes Pixie, the missing developer observability tool! Needless to say how important monitoring and observability is, especially in a
Java Building Native Covid19 Tracker CLI using Java, PicoCLI & GraalVM When it comes to building CLI apps, Java is not your first
Java Java 14 features: Text Blocks & Foreign-Memory Access API This is the fourth and last post in the blog post series
Java Java 14 features: Switch Expressions, JFR Event Streaming and more This is the third post in a series of blog posts highlighting
Docker Skaffold, OKE & OCIR! If you're working on cloud-native apps and containers, you probably already noticed
5 reasons to attend DevNexus 2020 We are writing these lines from 2 different beautiful cities; Brussels for