Redis, the popular open source in-memory data store, has been used as a persistent on-disk database that supports a variety of data structures such as lists, sets, sorted sets (with range queries), strings, geospatial indexes (with radius queries), bitmaps, hashes, and HyperLogLogs.
Today, the in-memory store is used to solve various problems in areas such as real-time messaging, caching, and statistic calculation. In this post, we'll look at how we can use Redis as buffer in the ELK Stack to ship, analyze, and visualize the data.
The objectif
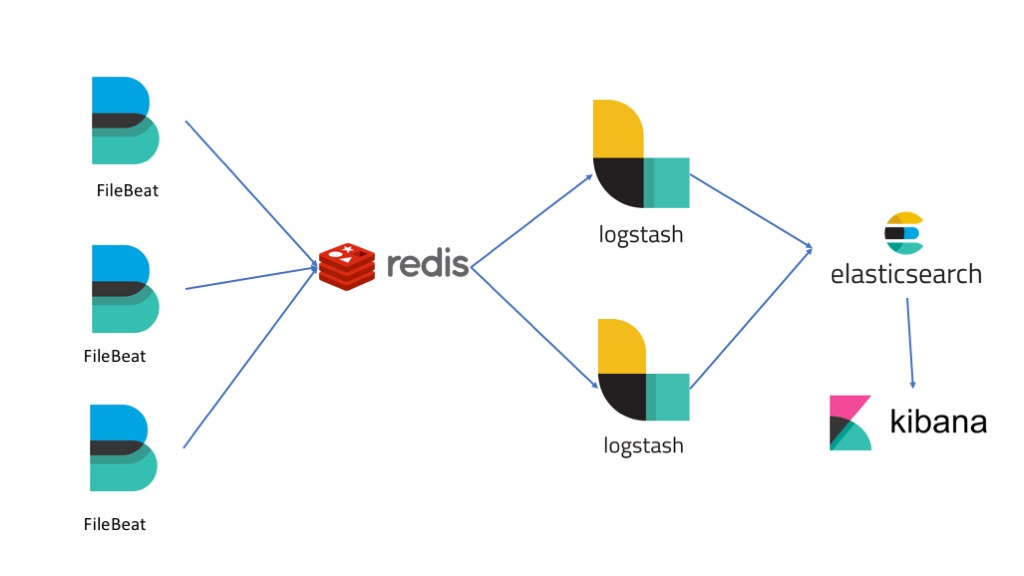
The image above describe what we're trying to achieve. I created some docker containers for:
- Filebeats agents: Containers running some apps to generate logs and filebeat.
- Redis Server: running in a container, installed from the default package repositories. No special configuration here.
- Multiple Logstash instances that have Redis as their input and ElasticSearch as their output
- Elastiserch container to store data.
- Kibana container to visualize sata.
Of course None of this was really necessary and all of this could have been put on a single node but I wanted to test a distributed setup.
Filebeat config
Filebeat is one of the best log file shippers out there today — it’s lightweight, supports SSL and TLS encryption, supports back pressure with a good built-in recovery mechanism, and is extremely reliable. It cannot, however, in most cases, turn your logs into easy-to-analyze structured log messages using filters for log enhancements. That’s the role played by Logstash.
It is a relatively new component that does what Syslog-ng, Rsyslog, or other lightweight forwarders in proprietary log forwarding stacks do. It monitors files and allows you to specific different outputs such as Elasticsearch, Logstash, Redis, or a file.
I used the following filebeat.yml configuration:
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
- input_type: log
paths:
- /app/logs/access*.logs
fields:
app_id: myapp
log_type: access-logs
- input_type: log
paths:
- /app/logs/some-other.log
fields:
app_id: myapp
log_type: app-logs
#------------------------------- Redis output ----------------------------------
output.redis:
hosts: ["XXX.XXX.XXX.XXX"]
password: "VeryStrongPAssword"
key: "filebeat"
db: 0
timeout: 5
Why Redis
Elasticsearch (or any search engine) can be an operational nightmare. Indexing can bog down. Searches can take down your cluster. Your data might have be reindexed for a whole variety of reasons.
So the goal of putting Redis in between your event sources and your parsing and processing is to only index/parse as fast as your nodes and database can handle it so you can pull from the event stream instead of having events pushed into your pipeline.
if you run "redis_cli monitor", you can see what's going on on your redis server: filebeat sending data and logstash asking for it.
1505464826.632292 [0 127.0.0.1:55642] "evalsha" "3236c446d3b876265fe40ac665cb6dc17e6242b0" "1" "filebeat" "124"
1505464826.632361 [0 lua] "lrange" "filebeat" "0" "124"
1505464826.632377 [0 lua] "ltrim" "filebeat" "125" "-1"
1505464826.767852 [0 192.168.1.184:39874] "RPUSH" "filebeat" "{\"@timestamp\":\"2017-09-15T10:20:21.590Z\",\"beat\":{\"hostname\":\"myhost\",\"name\":\"somename\",\"version\":\"5.6.0\"},\"fields\":{\"app_id\":\"myapp\",\"log_type\":\"app-logs\"},\"input_type\":\"log\",\"message\":\"api1 - - - 2017-09-15 12:20:12.766+0200 [http-nio-8090-exec-3] INFO o.s.s.l.SpringSecurityLdapTemplate - Ignoring PartialResultException\",\"offset\":28959,\"source\":\"/app/backend/api/tomcat/logs/app.log\",\"type\":\"log\"}" "{\"@timestamp\":\"2017-09-15T10:20:21.590Z\",\"beat\":{\"hostname\":\"myhost\",\"name\":\"somename\",\"version\":\"5.6.0\"},\"fields\":{\"app_id\":\"myapp\",\"log_type\":\"app-logs\"},\"input_type\":\"log\",\"message\":\"api1 - - - 2017-09-15 12:20:15.867+0200 [http-nio-8090-exec-1] INFO o.s.s.l.SpringSecurityLdapTemplate - Ignoring PartialResultException\",\"offset\":29099,\"source\":\"/app/backend/api/tomcat/logs/app.log\",\"type\":\"log\"}"
1505464826.882804 [0 127.0.0.1:55642] "evalsha" "3236c446d3b876265fe40ac665cb6dc17e6242b0" "1" "filebeat" "124"
1505464826.882857 [0 lua] "lrange" "filebeat" "0" "124"
1505464826.882877 [0 lua] "ltrim" "filebeat" "125" "-1"
1505464826.885339 [0 127.0.0.1:55642] "evalsha" "3236c446d3b876265fe40ac665cb6dc17e6242b0" "1" "filebeat" "124"
1505464826.885366 [0 lua] "lrange" "filebeat" "0" "124"
1505464826.885373 [0 lua] "ltrim" "filebeat" "125" "-1"
1505464827.135879 [0 127.0.0.1:55642] "evalsha" "3236c446d3b876265fe40ac665cb6dc17e6242b0" "1" "filebeat" "124"
1505464827.135964 [0 lua] "lrange" "filebeat" "0" "124"
1505464827.135992 [0 lua] "ltrim" "filebeat" "125" "-1"
1505464827.386558 [0 127.0.0.1:55642] "evalsha" "3236c446d3b876265fe40ac665cb6dc17e6242b0" "1" "filebeat" "124"
The RPUSH shows when an event was processed from /app/backend/api/tomcat/logs/app.log and then split into multiple log entries in JSON. This was generated when I called the api.
We see also logtash looking for 125 entries in the list with the LRANGE command. Most of the time this will return and empty list.
127.0.0.1:6379> lrange "filebeat" 0 124
(empty list or set)
127.0.0.1:6379>
Logstash: where the magic happens
Logstash configuration is pretty simple, we specufy redis and input and elasticsearch as output:
input {
redis {
password => "VeryStrongPAssword"
data_type => "list"
key => "filebeat"
}
}
output {
elasticsearch {}
}
The one I'm using is a bit more longer, because it contains some filter based on log type (access or app logs that I specified on the field part for filebeat configuration)
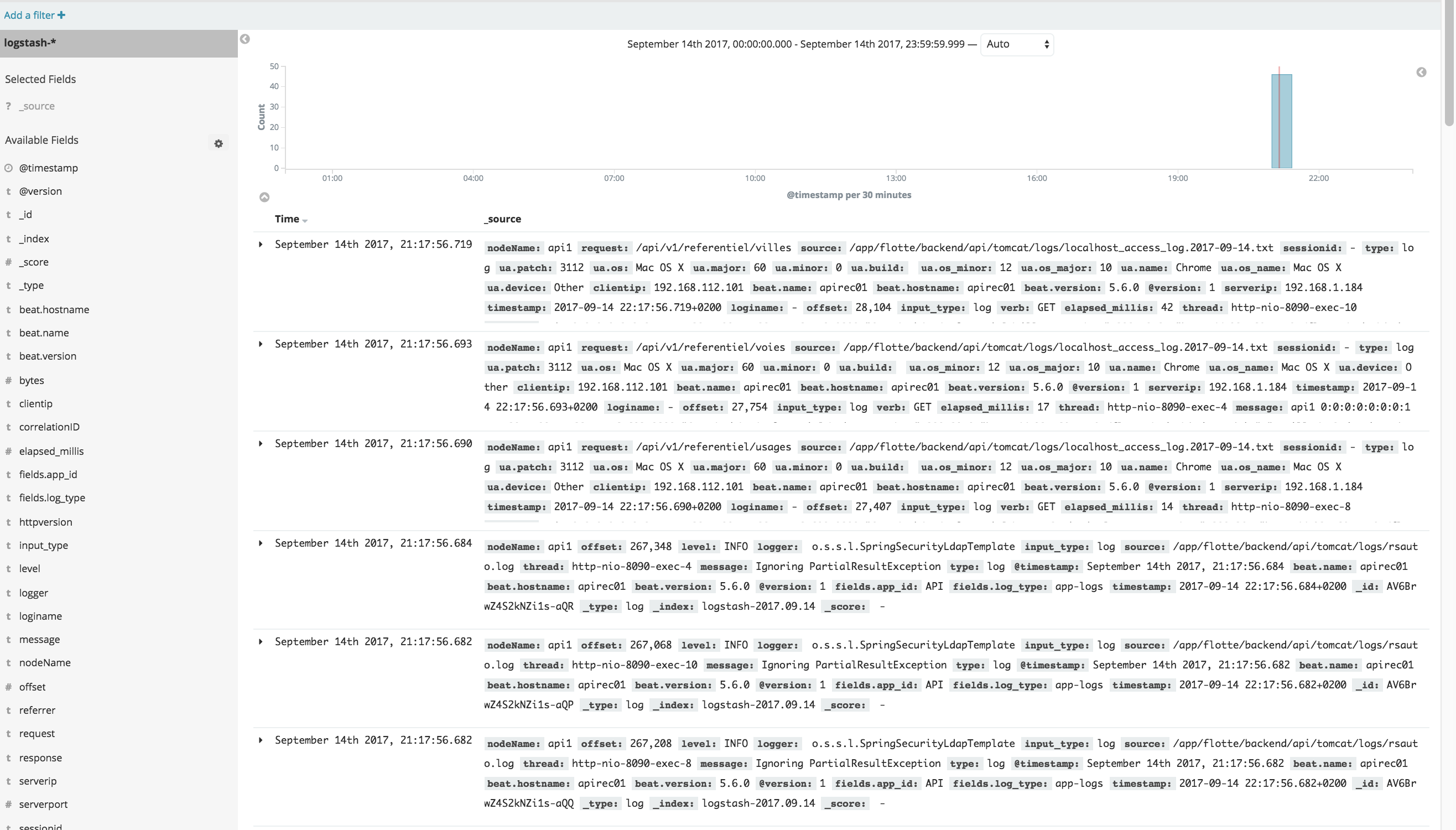
The result
The image below shows logs shipped from my running apps containers. nothing fancy, just logs data