
This is the 3rd post in a blog series that wrap up some key fundamentals of git. Today, I'll highlight some useful and underestimated git commands.
Git revert: Rolling back changes
It always happens! Perhaps you didn’t have enough coffee that morning, or it was just before lunch. Somehow though, that bug got into the repository, and now you need to get it out. Luckily, git revert is just the scalpel you need to extract that bad commit.
The “revert” command works like so: it basically reverses whatever changes made in the commit passed in by figuring out how to undo the changes introduced by the commit and appends a new commit with the resulting content. This prevents Git from losing history, which is important for the integrity of your revision history and for reliable collaboration.
So basicly you can pass in any SHA for any commit to revert those changes. Of course, if the commit that you want to revert doesn’t apply cleanly you’re going to have to manually resolve the merge.
Git blame: Tracing changes in a file
Let's agree on one thing first, this command has a negative-sounding name! But despite that I find it very useful and can be used to determine when a certain change was made.
To find out who changed a file, you can run git blame against a single file, and you get a breakdown of the file, line-by-line, with the change that last affected that line. It also prints out the timestamp and author information as well:
e2b0895d (Saaidi yassine 2017-05-10 15:26:58 +0100 10) import javax.servlet.http.HttpServletRequest;
2c3d64cb (aboullaite mohammed 2017-06-19 23:47:49 +0000 12) import com.peaqock.repository.CounterRepository;
2c3d64cb (aboullaite mohammed 2017-06-19 23:47:49 +0000 13) import com.peaqock.repository.VlAnRepository;
00000000 (Not Committed Yet 2017-07-15 21:40:41 +0100 14) import com.peaqock.service.email.EmailSender;
The timestamps and abbreviated commit hashes show the changes were introduced sequentially, but in this contrived example it's easy to see. Since Git has full information about the committer, it can show you the person's name (-n), or the persons e-mail address(-e)
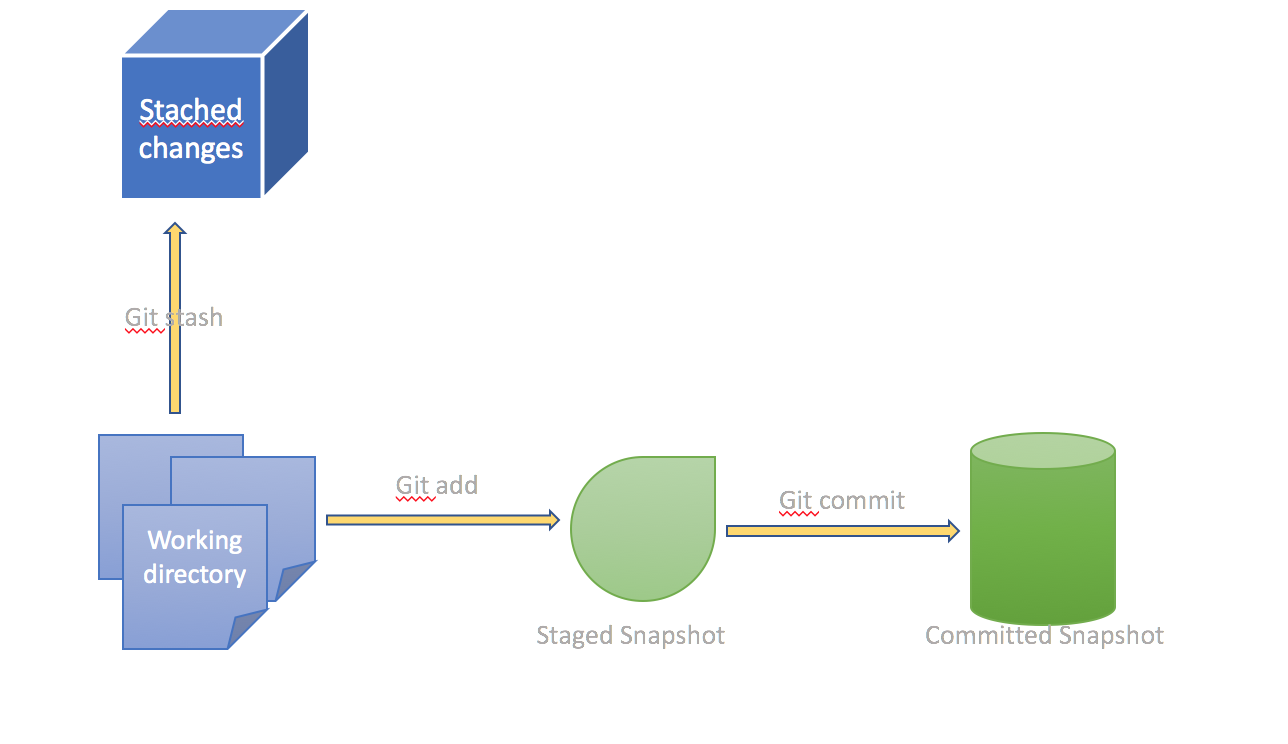
Git stash: Saving changes
Often, when you’ve been working on part of your project, things are in a messy state and you want to switch branches for a bit to work on something else. The problem is, you don’t want to do a commit of half-done work just so you can get back to this point later. The answer to this issue is the git stash command.
Stashing takes the dirty state of your working directory – that is, your modified tracked files and staged changes – and saves it on a stack of unfinished changes that you can reapply at any time. In other words git stash is a bit like git reset --hard, it gives you a clean working directory, but it also records your incomplete changes internally. After fixing the critical bug or finishing an urgent feature, you can re-apply these changes and pick up where you left off. You can think of git stash as a "pause button" for your in-progress work.
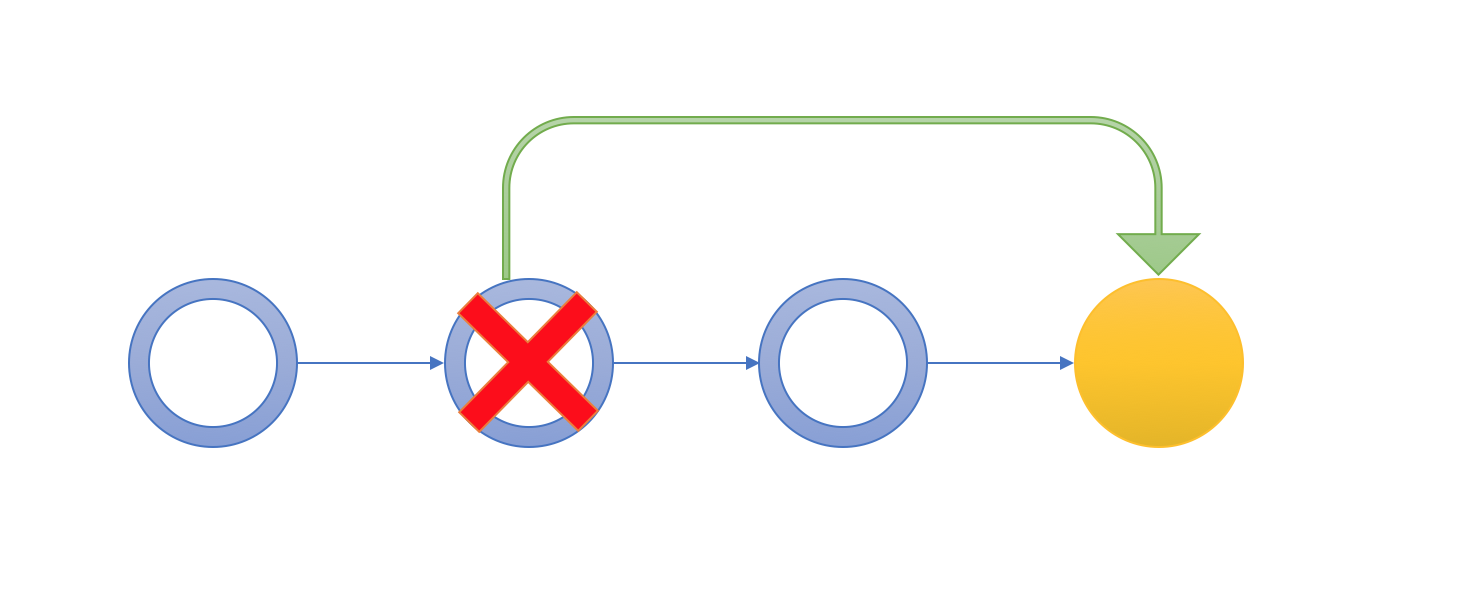
Git Bisect: The process of elimination
The slowest, most tedious way of finding a bad git commit is something we've all done before. You checkout some old commit, make sure the broken code isn't there, then checkout a slightly newer commit, check again, and repeat over and over until you find the flawed commit.
Using git bisect is a much better way. It's like a little wizard that walks you through recent commits, asks you if they are good or bad, and narrows down the broken commit.
The idea behind git bisect is to perform a binary search in the history to find a particular regression. Imagine that you have the following development history:
... --- 0 --- 1 --- 2 --- 3 --- 4* --- 5 --- current
You know that your program is not working properly at the current revision, and that it was working at the revision 0. So the regression was likely introduced in one of the commits 1, 2, 3, 4, 5, current.
You could try to check out each commit, build it, check if the regression is present or not. If there is a large number of commits, this can take a long time. This is a linear search. We can do better by doing a binary search. This is what the git bisect command does. At each step it tries to reduce the number of revisions that are potentially bad by half.
Git cherry-pick:
Here's a scenario: You're working in a feature branch that isn't quite ready for a full merge but you do have a few commits in there that you want to push to master (for a release or whatever reason). This is just one of possibly many situations where making use of Git's cherry-pick command might prove useful.
What git cherry-pick does, basically, is take a commit from somewhere else, and "play it back" wherever you are right now. Because this introduces the same change with a different parent, Git builds a new commit with a different ID.
How about an example! First of all, use git log or the awesome GitX tool to see exactly which commit you want to pick. An example:
dd2e86 - 946992 - 9143a9 - a6fd86 - 5a6057 [master]
\
76cada - 62ecb3 - b886a0 [feature]
Let’s say you’ve written some code in commit 62ecb3 of the feature branch that is very important right now. It may contain a bug fix or code that other people need to have access to now. Whatever the reason, you want to have commit 62ecb3 in the master branch right now, but not the other code you’ve written in the feature branch.
Here comes git cherry-pick. In this case, 62ecb3 is the cherry and you want to pick it!
git checkout master
git cherry-pick 62ecb3
That’s all. 62ecb3 is now applied to the master branch and commited (as a new commit) in master. cherry-pick behaves just like merge. If git can’t apply the changes (e.g. you get merge conflicts), git leaves you to resolve the conflicts manually and make the commit yourself.
git add -p: Interactive staging
One of the things that is pretty much unique to Git is the index (also known as the cache or staging area).
The index is the place where you prepare your next commit. In other systems whenever you make a commit, all the changes you made in your working copy are committed.
With Git you first add all the changes you want to be in the next commit to the index via git add (or remove a file with git rm). Normally, calling git add <file> will add all the changes in that file to the index, but add supports an interesting option: --patch, or -p for short. When you pass this option to add, instead of immediately adding all the changes in the file to the index, it goes through each change and asks you what you want to do.
hat's it. Hopefully you learned a thing or two ;)