
Spring Batch is a lightweight, comprehensive batch framework designed to enable the development of robust batch applications vital for the daily operations of enterprise systems. Spring Batch provides reusable functions that are essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management. It also provides more advanced technical services and features that will enable extremely high-volume and high performance batch jobs through optimization and partitioning techniques.
Let’s start by using Spring Batch to implement a read-write use case.
Anatomy of the read-write step
Since read-write (and copy) scenarios are common in batch applications, Spring Batch provides specific support for this use case. Spring Batch includes many ready-to-use components to read and write from and to data stores like files and databases. Spring Batch also includes a specific batch-oriented algorithm to handle the execution flow called chunk processing. Below figure illustrates the principle of chunk processing.
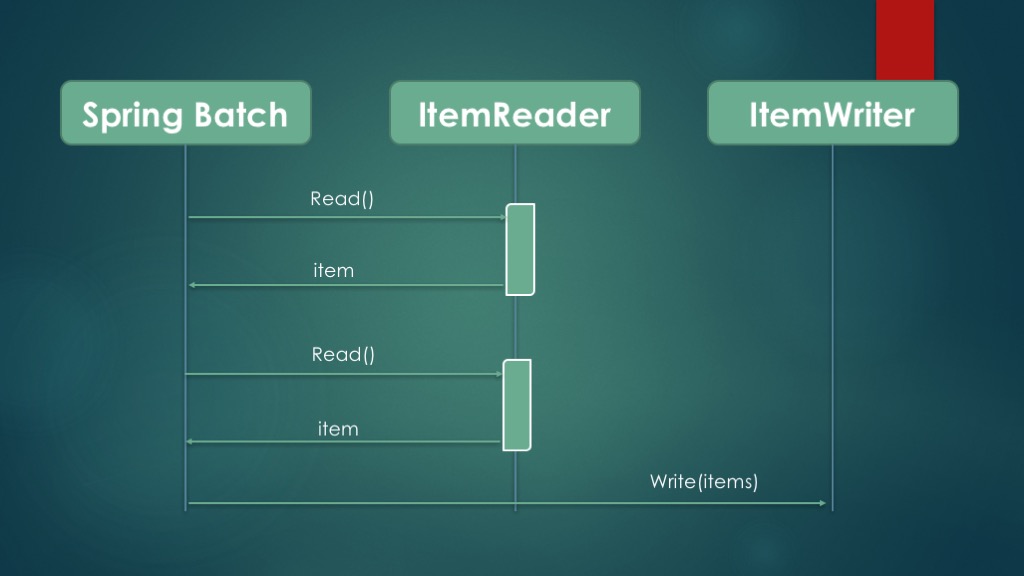
Spring Batch handles read-write scenarios by managing an ItemReader and an ItemWriter. Spring Batch collects items one at a time from the item reader into a chunk, where the chunk size is configurable. Spring Batch then sends the chunk to the item writer and goes back to using the item reader to create another chunk, and so on until the input is exhausted. This is what we call chunk processing.
CHUNK PROCESSING
Chunk processing is particularly well suited to handle large data operations since items are handled in small chunks instead of processed all at once. Practically speaking, a large file won’t be loaded in memory, instead it will be streamed, which is more efficient in terms of memory consumption. Chunk processing allows more flexibility to manage the data flow in a job. Spring Batch also handles transactions and errors around read and write operations.
Speaking of flexibility, Spring Batch provides an optional processing step to chunk processing: items read can be processed (transformed) before being sent to the ItemWriter. The ability to process an item is useful when you don’t want to write an item as is. The component that handles this transformation is an implementation of the ItemProcessor interface. Because item processing in Spring Batch is optional, the illustration of chunk processing shown in the first figure is still valid. The below figure illustrates chunk processing combined with item processing.
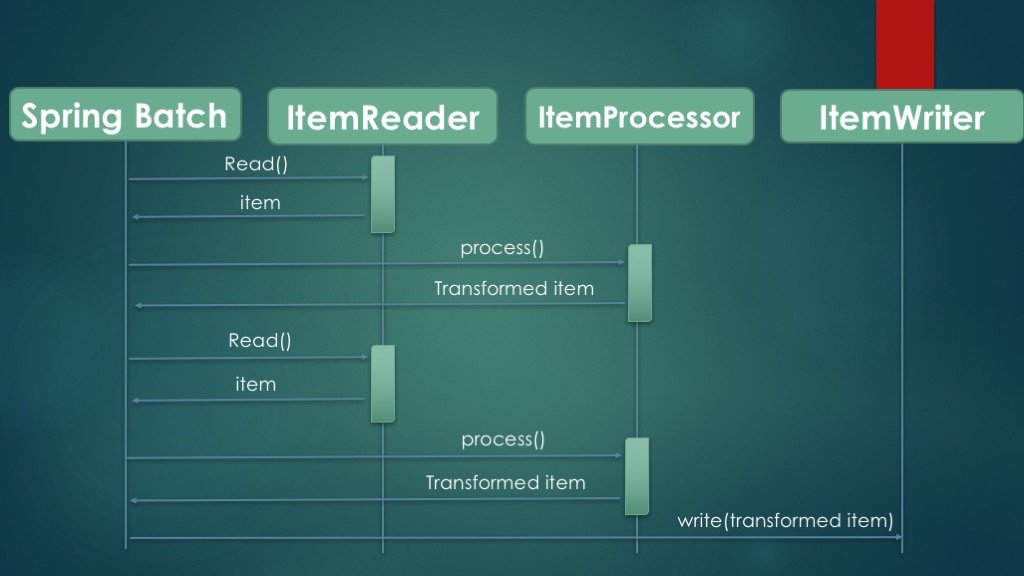
What can be done in an ItemProcessor? You can perform any transformations you need on each item before it is sent to the ItemWriter. This is where we implement the logic to transform the data from the input format into the format expected by the target system. Spring Batch also lets you validate and filter an input item; if you return null from the ItemProcessor method process, processing for that item will stop and the item will not be inserted into the database.
Spring Batch Jobs
Spring Batch provides the FlatFileItemReader class to read records from a flat file. To use a FlatFileItemReader, you need to configure some Spring beans and implement a component that creates domain objects from what the FlatFileItemReader reads; Spring Batch will handle the rest. You can kiss all your old I/O boilerplate code goodbye and focus on the structure of the data and how to exploit that data.
The source code of this demo project is available on github
domain class
public class Student {
private String firstName, lastName, email;
private int age;
public Student() {
}
(...)
Steps Configuration
Writing from file to database
@Configuration
public class Step1 {
@Bean
public FlatFileItemReader<Student> fileReader(@Value("${input}") Resource in) throws Exception {
return new FlatFileItemReaderBuilder<Student>()
.name("file-reader")
.resource(in)
.targetType(Student.class)
.linesToSkip(1)
.delimited().delimiter(",").names(new String[]{"firstName", "lastName", "email", "age"})
.build();
}
@Bean
public JdbcBatchItemWriter<Student> jdbcWriter(DataSource ds) {
return new JdbcBatchItemWriterBuilder<Student>()
.dataSource(ds)
.sql("insert into STUDENT( FIRST_NAME, LAST_NAME, EMAIL, AGE) values (:firstName, :lastName, :email, :age)")
.beanMapped()
.build();
}
}
Writing from Database to a CSV file
@Configuration
public class Step2 {
@Bean
public ItemReader<Map<Integer, Integer>> jdbcReader(DataSource dataSource) {
return new JdbcCursorItemReaderBuilder<Map<Integer, Integer>>()
.dataSource(dataSource)
.name("jdbc-reader")
.sql("select COUNT(age) c, age a from STUDENT group by age")
.rowMapper((rs, i) -> Collections.singletonMap(rs.getInt("a"), rs.getInt("c")))
.build();
}
@Bean
public ItemWriter<Map<Integer, Integer>> fileWriter(@Value("${output}") Resource resource) {
return new FlatFileItemWriterBuilder<Map<Integer, Integer>>()
.name("file-writer")
.resource(resource)
.lineAggregator(new DelimitedLineAggregator<Map<Integer, Integer>>() {
{
setDelimiter(",");
setFieldExtractor(integerIntegerMap -> {
Map.Entry<Integer, Integer> next = integerIntegerMap.entrySet().iterator().next();
return new Object[]{next.getKey(), next.getValue()};
});
}
})
.build();
}
}
Job Configuration
@Configuration
@EnableBatchProcessing
public class Batch {
@Bean
Job job(JobBuilderFactory jbf,
StepBuilderFactory sbf,
Step1 step1,
Step2 step2) throws Exception {
Step s1 = sbf.get("file-db")
.<Student, Student>chunk(100)
.reader(step1.fileReader(null))
.writer(step1.jdbcWriter(null))
.build();
Step s2 = sbf.get("db-file")
.<Map<Integer, Integer>, Map<Integer, Integer>>chunk(100)
.reader(step2.jdbcReader(null))
.writer(step2.fileWriter(null))
.build();
return jbf.get("etl")
.incrementer(new RunIdIncrementer())
.start(s1)
.next(s2)
.build();
}
}
Spring Batch performs a lot of the work on our behalf: it reads the students from the flat file and imports them into the database.
For the write operation, we only created the logic to insert Students in the database. Putting these components together is straightforward thanks to Spring Boot and Spring batch.