Building Production-Grade RAG Systems: Architecture Deep Dive
In the first part, we explored the production challenges of RAG systems: latency, reliability, cost, quality, and observability. Now let's get our hands dirty with the actual architecture and implementation.
The codebase uses Java 25, Spring Boot 3.5.7, reactive programming with WebFlux, and follows production patterns you'd see in enterprise systems. Every design decision has a reason, and I'll explain the tradeoffs as we go.
Service Boundaries: Why Separation Matters
The system is split into three main modules:
common/ # Shared DTOs and tracing helpers
retriever/ # Reactive Weaviate/OpenSearch retriever service
orchestrator/ # Orchestration, caching, LLM routing, SSE
This separation isn't arbitrary. Each service has distinct scaling characteristics and failure modes:
- Retriever is CPU and I/O intensive, scales horizontally, and needs aggressive timeouts
- Orchestrator manages state (semantic cache), handles user connections (SSE), and coordinates the pipeline
- Common provides shared contracts (DTOs) and telemetry utilities that both services use
By isolating these responsibilities, we can scale the retriever independently during traffic spikes while keeping the orchestrator stable. If the retriever service crashes, the orchestrator can still serve cached responses.
The Retriever Service: Hybrid Search with Fallbacks
Let's start with document retrieval. The retriever service exposes a single endpoint:
POST /v1/retrieve
Request:
{
"text": "How does autoscaling work?",
"filters": {"section": "infrastructure"},
"topK": 5
}
Response:
[
{
"id": "doc-03-autoscaling",
"chunk": "Autoscaling combines HPA and KEDA...",
"score": 0.87,
"metadata": {
"source": "doc-03-autoscaling.md",
"section": "infrastructure"
}
}
]
The implementation is deceptively simple but primarily designed for resilience:
// retriever/src/main/java/me/aboullaite/rag/retriever/service/RetrieverService.java
@Service
public class RetrieverService {
private final WeaviateGateway weaviateGateway;
private final OpenSearchGateway openSearchGateway;
private final RetrieverProperties properties;
private final Timer retrievalLatency;
private final Counter fallbackCounter;
private final Tracer tracer;
public Mono<List<RetrievedDoc>> retrieve(Query query) {
int topK = query.topK() > 0 ? query.topK() : properties.getTopKDefault();
return Mono.defer(() -> executeRetrieval(query, topK));
}
private Mono<List<RetrievedDoc>> executeRetrieval(Query query, int topK) {
Span span = tracer.spanBuilder("rag.retrieve")
.setAttribute("rag.request.topK", topK)
.startSpan();
Timer.Sample sample = Timer.start(meterRegistry);
return weaviateGateway.search(query, topK)
.timeout(Duration.ofMillis(properties.getTimeoutMs()))
.onErrorResume(throwable -> fallback(query, topK, span, throwable))
.doOnNext(docs -> TracingUtils.recordRetrievedDocs(span, docs))
.doOnError(span::recordException)
.doFinally(signalType -> {
sample.stop(retrievalLatency);
span.end();
});
}
private Mono<List<RetrievedDoc>> fallback(Query query, int topK, Span parentSpan, Throwable throwable) {
boolean timeout = throwable instanceof TimeoutException;
log.warn("Primary vector search failed (timeout={}): {}", timeout, throwable.getMessage());
fallbackCounter.increment();
TracingUtils.recordFallback(parentSpan, timeout ? "weaviate-timeout" : throwable.getClass().getSimpleName());
if (!openSearchGateway.isEnabled()) {
return Mono.just(List.of());
}
return openSearchGateway.search(query, topK)
.doOnNext(docs -> TracingUtils.recordRetrievedDocs(parentSpan, docs));
}
}
Key Design Decisions
1. Reactive Streams with Project Reactor
Notice the return type: Mono<List<RetrievedDoc>>. This is Project Reactor's reactive type for 0-1 values. By using reactive programming:
- We avoid blocking threads during I/O
- Timeouts are first-class citizens (
.timeout(Duration.ofMillis(250))) - Error handling composes naturally (
.onErrorResume()) - Observability hooks integrate seamlessly (
.doOnNext(),.doFinally())
Spring Boot's WebFlux framework handles request threads efficiently, allowing the retriever to handle hundreds of concurrent requests without thread pool exhaustion.
2. Aggressive Timeouts
The default timeout is 250ms. That's intentionally tight. Why?
- Users expect sub-second responses
- Vector databases can have occasional slow queries (large result sets, index rebuilds, etc.)
- We'd rather fallback to lexical search than make users wait. That is of cource debatable and depends on what wre we optimazing for!
In load testing, this timeout triggers fallback ~5-15% of the time under heavy load, which is acceptable given the graceful degradation.
3. Observability at Every Step
Every retrieval is instrumented:
- OpenTelemetry Span: captures timing, document count, and fallback reasons
- Prometheus Timer: records latency histogram for p95/p99 analysis
- Prometheus Counter: tracks fallback frequency
When debugging production issues, we can simply filter Tempo traces by rag.fallback.reason=weaviate-timeout to see exactly which requests degraded.
4. Lexical Fallback via OpenSearch
Weaviate is great for semantic search, but sometimes you need exact term matching. OpenSearch provides BM25 ranking, which excels at:
- Acronyms (e.g., "HPA", "KEDA", "SSE")
- Version numbers (e.g., "Java 25", "Spring Boot 3.5.7")
- Exact phrases (e.g., "Server-Sent Events")
The fallback is a deliberate hybrid retrieval strategy. Some RAG systems use re-rankers to combine vector and lexical signals; here, we use fallback for simplicity while maintaining quality.
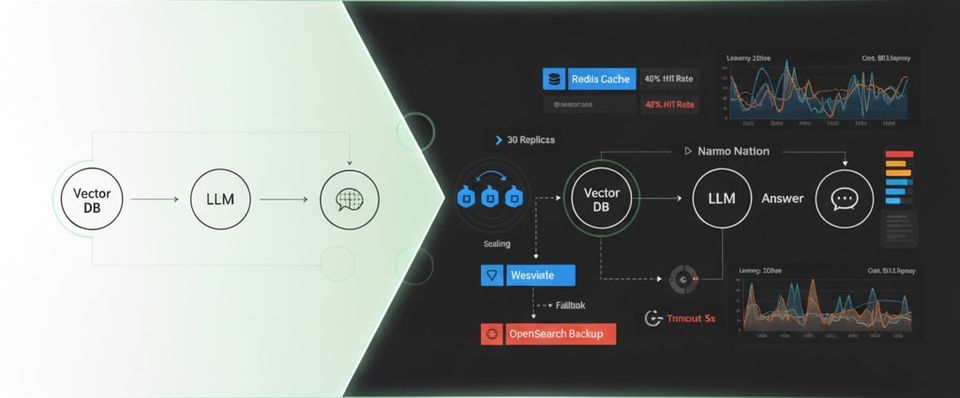
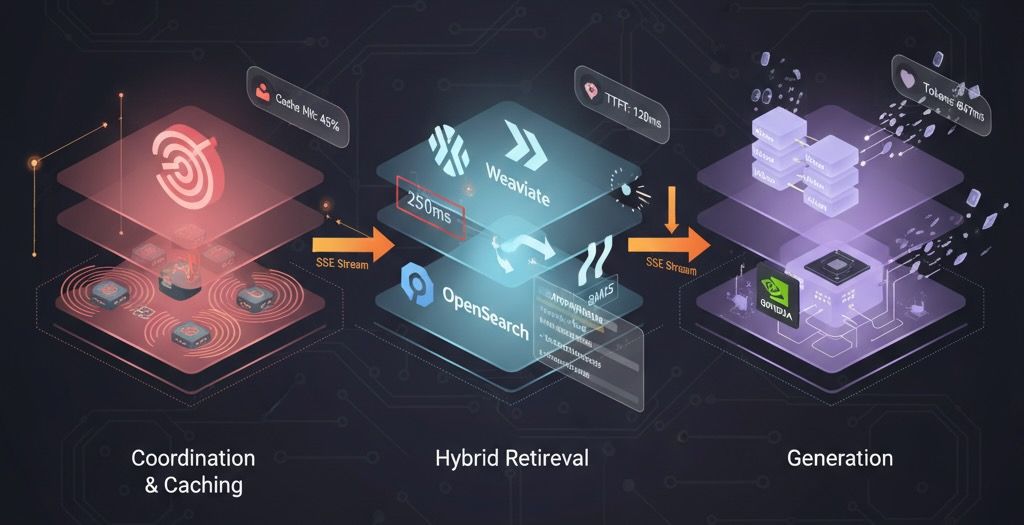
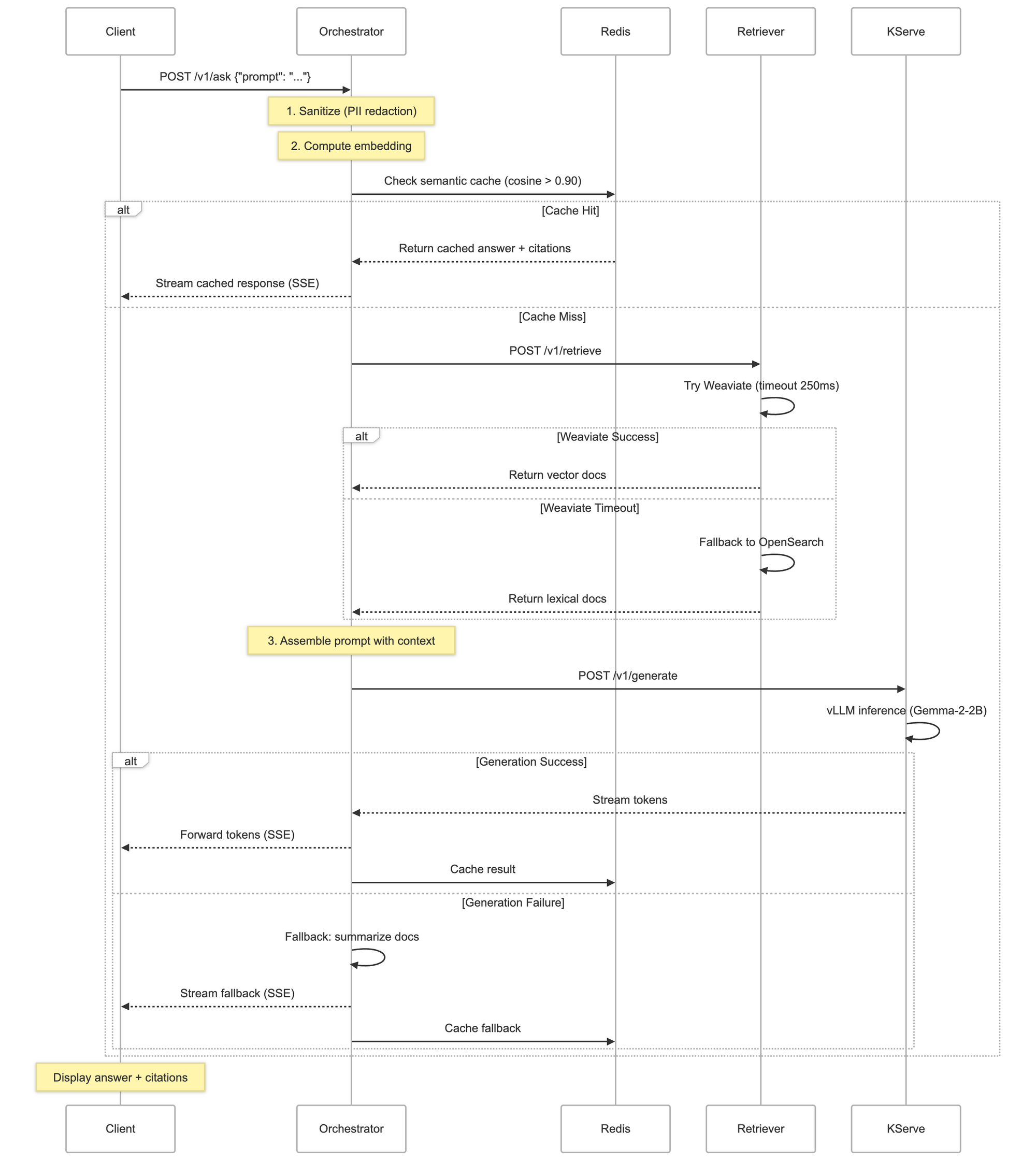
The Orchestrator Service: Coordination and Caching
The orchestrator is the brain of the system. It coordinates caching, retrieval, prompt assembly, generation, and streaming. Let's walk through the request flow.
Request Flow Diagram
Semantic Cache Implementation
The semantic cache is the secret weapon for both latency and cost optimization. Here's the code:
// orchestrator/src/main/java/me/aboullaite/rag/orchestrator/cache/SemanticCacheService.java
@Service
public class SemanticCacheService {
private static final String CACHE_INDEX = "rag:cache:index";
private static final String CACHE_KEY_PREFIX = "rag:cache:";
private static final double SIMILARITY_THRESHOLD = 0.90;
private static final Duration CACHE_TTL = Duration.ofMinutes(10);
private final RedisTemplate<String, String> redisTemplate;
public Mono<CacheHit> lookup(String normalizedQuery, double[] embedding) {
return Mono.fromCallable(() -> {
Set<String> keys = redisTemplate.opsForSet().members(CACHE_INDEX);
if (keys == null || keys.isEmpty()) {
return null;
}
double maxSimilarity = 0.0;
CacheEntry bestMatch = null;
for (String key : keys) {
String json = redisTemplate.opsForValue().get(key);
if (json == null) continue;
CacheEntry entry = deserialize(json);
double similarity = SimilarityUtils.cosineSimilarity(embedding, entry.embedding());
if (similarity > maxSimilarity && similarity >= SIMILARITY_THRESHOLD) {
maxSimilarity = similarity;
bestMatch = entry;
}
}
return bestMatch != null ? new CacheHit(bestMatch, maxSimilarity) : null;
}).subscribeOn(Schedulers.boundedElastic());
}
public Mono<Void> put(String normalizedQuery, double[] embedding,
GenerationResponse response, List<RetrievedDoc> docs) {
return Mono.fromRunnable(() -> {
String key = CACHE_KEY_PREFIX + UUID.randomUUID();
CacheEntry entry = new CacheEntry(
normalizedQuery,
embedding,
response.answer(),
response.citations(),
docs.stream().map(RetrievedDoc::id).toList(),
System.currentTimeMillis()
);
String json = serialize(entry);
redisTemplate.opsForValue().set(key, json, CACHE_TTL);
redisTemplate.opsForSet().add(CACHE_INDEX, key);
}).subscribeOn(Schedulers.boundedElastic()).then();
}
}
Why Cosine Similarity Threshold 0.90?
This threshold balances precision and recall:
- Too low (e.g., 0.70): You'd match dissimilar queries, returning wrong cached answers
- Too high (e.g., 0.98): You'd miss legitimate matches, reducing cache hit rate
At 0.90, queries like:
- "How does autoscaling work?"
- "Explain the autoscaling mechanism"
- "What is the autoscaling strategy?"
...all match and reuse the same cached answer. But unrelated queries like "How do I ingest data?" won't match.
In load testing with realistic query distributions, 0.90 yields ~45% cache hit rate, cutting LLM costs nearly in half.
This is based on my tests and use cases, don't just rely on these numbers, please perform your own testing. Your numbers can be different.
Deterministic Embeddings
For this demo, I'm using deterministic 8-dimensional embeddings generated via SHA-256 hashing:
// common/src/main/java/me/aboullaite/rag/common/embedding/DeterministicEmbedding.java
public class DeterministicEmbedding {
public static double[] embed(String text) {
byte[] hash = MessageDigest.getInstance("SHA-256").digest(text.getBytes());
double[] embedding = new double[8];
for (int i = 0; i < 8; i++) {
embedding[i] = (hash[i] & 0xFF) / 255.0;
}
return normalize(embedding);
}
}
Why deterministic embeddings?
- No external embedding service dependency for the demo
- Reproducible cache behavior in tests
- Instant embedding computation (no API latency)
In production, we'd need to use proper sentence embeddings (e.g., all-MiniLM-L6-v2 via Hugging Face or OpenAI text-embedding-3-small). The cache logic remains identical, we just have to swap the embedding function.
Prompt Assembly and Citation Tracking
Once documents are retrieved, we need to construct a prompt that:
- Provides clear instructions to the LLM
- Injects retrieved context
- Enforces citation requirements
- Handles edge cases (no documents, partial results, etc.)
// orchestrator/src/main/java/me/aboullaite/rag/orchestrator/prompt/PromptAssembler.java
@Component
public class PromptAssembler {
public PromptBundle assemble(String userPrompt, List<RetrievedDoc> docs) {
if (docs.isEmpty()) {
return new PromptBundle(
noContextPrompt(userPrompt),
List.of(),
List.of()
);
}
StringBuilder prompt = new StringBuilder();
prompt.append("You are a helpful assistant. Answer the question based ONLY on the provided documents.\n\n");
prompt.append("Documents:\n");
List<String> citations = new ArrayList<>();
List<CitationInfo> citationDetails = new ArrayList<>();
for (int i = 0; i < docs.size(); i++) {
RetrievedDoc doc = docs.get(i);
String citationId = doc.id();
citations.add(citationId);
citationDetails.add(new CitationInfo(
citationId,
doc.metadata().source(),
doc.metadata().section()
));
prompt.append(String.format("[%s] %s\n\n", citationId, doc.chunk()));
}
prompt.append("Question: ").append(userPrompt).append("\n\n");
prompt.append("Instructions:\n");
prompt.append("- Answer ONLY using information from the provided documents\n");
prompt.append("- Cite sources using [doc-id] notation\n");
prompt.append("- If the documents don't contain enough information, say 'I don't know'\n");
prompt.append("- Be concise and accurate\n\n");
prompt.append("Answer:");
return new PromptBundle(prompt.toString(), citations, citationDetails);
}
private String noContextPrompt(String userPrompt) {
return "You are a helpful assistant. The user asked: " + userPrompt +
"\n\nNo relevant documents were found. Please respond with: I don't know.";
}
}
Citation Enforcement
Notice the explicit instructions:
- "Answer ONLY using information from the provided documents"
- "Cite sources using [doc-id] notation"
- "If the documents don't contain enough information, say 'I don't know'"
LLMs are surprisingly good at following these instructions when they're clear and emphatic. In testing with Gemma-2-2B, citation compliance is >85% for well-formed prompts.
The PromptBundle record encapsulates:
public record PromptBundle(
String prompt, // Full prompt sent to LLM
List<String> citations, // [doc-03-autoscaling, doc-09-infrastructure]
List<CitationInfo> citationDetails // Full metadata for UI rendering
) {}
This separation allows the orchestrator to:
- Send a clean prompt to the LLM
- Return structured citations to the client
- Track which documents contributed to each answer (for cache invalidation, analytics, etc.)
LLM Integration: KServe + vLLM
The LLM layer uses KServe (Kubernetes serving framework) with vLLM runtime to host Gemma-2-2B-it (instruction-tuned).
Why KServe?
KServe provides:
- Autoscaling: Scale-to-zero when idle, scale-up on demand
- GPU management: Automatic GPU resource allocation
- Inference optimization: vLLM uses PagedAttention for efficient memory usage
- Standardized API: OpenAI-compatible
/v1/chat/completionsendpoint
The InferenceService definition:
# deploy/kserve-vllm.yaml
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: rag-llm
namespace: rag
spec:
predictor:
minReplicas: 0 # Scale to zero when idle
maxReplicas: 1
scaleTarget: 1
scaleMetric: concurrency
model:
runtime: vllm-runtime
modelFormat:
name: huggingface
args:
- --model
- google/gemma-2-2b-it
- --dtype
- auto
- --max-model-len
- "4096"
resources:
limits:
nvidia.com/gpu: 1
cpu: "3"
memory: 12Gi
requests:
cpu: "2"
memory: 8Gi
vLLM Runtime Configuration
vLLM is a high-performance inference engine optimized for LLMs. Key features:
- PagedAttention: Reduces memory fragmentation, increases throughput
- Continuous batching: Processes multiple requests efficiently
- Quantization support:
--dtype autoenables FP16/BF16 for faster inference
With Gemma-2-2B on an L4 GPU (24GB), vLLM achieves:
- Time-to-first-token (TTFT): ~100-300ms
- Throughput: ~50-80 tokens/sec
- Concurrent requests: 4-8 (depending on sequence length)
LLM Client Implementation
The orchestrator calls KServe via a reactive client:
// orchestrator/src/main/java/me/aboullaite/rag/orchestrator/client/LlmClient.java
@Component
public class LlmClient {
private final WebClient webClient;
private final OrchestratorProperties properties;
public Mono<LlmResponse> generate(String prompt) {
Map<String, Object> request = Map.of(
"model", properties.getModelName(),
"messages", List.of(
Map.of("role", "user", "content", prompt)
),
"max_tokens", properties.getMaxTokens(),
"temperature", properties.getTemperature()
);
long startNano = System.nanoTime();
AtomicLong ttftNano = new AtomicLong(0);
return webClient.post()
.uri("/v1/chat/completions")
.bodyValue(request)
.retrieve()
.bodyToMono(Map.class)
.map(response -> {
if (ttftNano.get() == 0) {
ttftNano.set(System.nanoTime() - startNano);
}
String content = extractContent(response);
int tokens = estimateTokens(content);
long ttftMillis = ttftNano.get() / 1_000_000;
return new LlmResponse(content, tokens, ttftMillis);
})
.timeout(Duration.ofSeconds(properties.getGenerationTimeoutSeconds()));
}
}
Time-to-First-Token (TTFT) is a critical metric for user experience. Measuring it accurately requires:
- Start timer when request begins
- Capture timestamp on first response byte
- Calculate delta in milliseconds
This metric appears in OpenTelemetry spans as rag.ttft_ms, allowing us to track degradation trends in Grafana.
Streaming Responses with Server-Sent Events
One of the best UX improvements in modern LLM applications is streaming. Instead of waiting 3+ seconds for the complete answer, users see tokens as they're generated.
SSE Endpoint
// orchestrator/src/main/java/me/aboullaite/rag/orchestrator/web/AskController.java
@GetMapping(value = "/v1/ask/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ServerSentEvent<String>> askStream(
@RequestParam String prompt,
@RequestParam(required = false) Map<String, String> filters,
@RequestParam(required = false, defaultValue = "5") Integer topK) {
return askService.askStreaming(prompt, filters, topK)
.map(chunk -> {
if (chunk.isComplete()) {
return ServerSentEvent.<String>builder()
.event("complete")
.data(toJson(chunk))
.build();
} else {
return ServerSentEvent.<String>builder()
.event("token")
.data(chunk.token())
.build();
}
});
}
Event Types:
token: Individual generated tokens (streamed progressively)complete: Final event containing citations and metadata
Client-side consumption (JavaScript):
const eventSource = new EventSource('/v1/ask/stream?prompt=How+does+caching+work');
eventSource.addEventListener('token', (event) => {
document.getElementById('answer').textContent += event.data;
});
eventSource.addEventListener('complete', (event) => {
const result = JSON.parse(event.data);
displayCitations(result.citations);
eventSource.close();
});
Progressive rendering dramatically improves perceived performance. Users engage with partial responses while generation continues, reducing perceived wait time by 50-70%.
Request Orchestration: Putting It All Together
Here's the core orchestration logic that ties everything together:
// orchestrator/src/main/java/me/aboullaite/rag/orchestrator/service/AskService.java
public Mono<GenerationResponse> ask(String prompt, Map<String, String> filters, Integer topK) {
String sanitizedPrompt = redact(prompt); // PII redaction
double[] embedding = embeddingService.embed(sanitizedPrompt);
Span span = tracer.spanBuilder("rag.ask").startSpan();
Timer.Sample sample = Timer.start(meterRegistry);
return cacheService.lookup(sanitizedPrompt, embedding)
.flatMap(hit -> onCacheHit(hit, span))
.switchIfEmpty(Mono.defer(() -> {
cacheMissCounter.increment();
TracingUtils.recordCacheHit(span, false);
return generateWithRetrieval(sanitizedPrompt, filters, topK, embedding, span);
}))
.doOnError(span::recordException)
.doFinally(signalType -> {
sample.stop(askLatency);
span.end();
});
}
private Mono<GenerationResponse> generateWithRetrieval(
String sanitizedPrompt,
Map<String, String> filters,
Integer topK,
double[] embedding,
Span parentSpan) {
Query query = new Query(sanitizedPrompt, filters, topK);
return retrieverClient.retrieve(query)
.flatMap(docs -> produceAnswer(sanitizedPrompt, docs, embedding, parentSpan))
.switchIfEmpty(Mono.defer(() -> produceAnswer(sanitizedPrompt, List.of(), embedding, parentSpan)));
}
private Mono<GenerationResponse> produceAnswer(
String sanitizedPrompt,
List<RetrievedDoc> docs,
double[] embedding,
Span parentSpan) {
PromptBundle promptBundle = promptAssembler.assemble(sanitizedPrompt, docs);
return llmClient.generate(promptBundle.prompt())
.map(response -> toGenerationResponse(response, promptBundle, false, parentSpan))
.flatMap(response -> cacheService.put(sanitizedPrompt, embedding, response, docs)
.thenReturn(response))
.onErrorResume(ex -> {
log.warn("LLM call failed, using fallback: {}", ex.getMessage());
fallbackCounter.increment();
TracingUtils.recordFallback(parentSpan, ex.getClass().getSimpleName());
GenerationResponse fallback = fallbackResponse(docs, promptBundle.citationDetails());
return cacheService.put(sanitizedPrompt, embedding, fallback, docs)
.onErrorResume(e -> Mono.empty())
.thenReturn(fallback);
});
}
Reactive Composition Explained
The flow uses reactive operators to compose asynchronous operations:
cacheService.lookup(): Check cache (non-blocking I/O to Redis).flatMap(hit -> onCacheHit()): If cache hit, return immediately.switchIfEmpty(Mono.defer(() -> ...)): If cache miss, proceed to retrievalretrieverClient.retrieve(): Call retriever service (HTTP call).flatMap(docs -> produceAnswer()): Generate answer with retrieved docsllmClient.generate(): Call LLM (HTTP streaming).flatMap(response -> cacheService.put()): Cache the result.onErrorResume(ex -> fallbackResponse()): Graceful degradation on error.doFinally(): Stop timer and close span (always executes)
This composition is non-blocking. No threads wait on I/O. Spring WebFlux dispatches work efficiently across an event loop, enabling high concurrency with minimal thread overhead.
Component Summary
Let's recap the key components and their roles:
| Component | Responsibility | Technology | Scaling Strategy |
|---|---|---|---|
| Orchestrator | Request coordination, caching, streaming | Spring WebFlux, Redis | Horizontal (stateless except cache) |
| Retriever | Hybrid search (vector + lexical) | Spring WebFlux, Weaviate, OpenSearch | HPA (CPU) + KEDA (RPS) |
| Semantic Cache | Similarity-based response caching | Redis, cosine similarity | Vertical (single instance for consistency) |
| Vector Store | Semantic document search | Weaviate | Managed/external service |
| Lexical Store | Fallback keyword search | OpenSearch | Managed/external service |
| LLM Serving | Model inference with GPU | KServe, vLLM, Gemma-2-2B | KServe autoscaling (scale-to-zero) |
| Observability | Metrics, traces, dashboards | Prometheus, Tempo, Grafana, OTEL | N/A (infrastructure) |
Why This Architecture Scales
The components here aren't just for demos. they're a good starting point to build production systems:
- Service Isolation: Retriever and orchestrator scale independently
- Reactive Programming: Non-blocking I/O maximizes throughput
- Timeouts Everywhere: Aggressive timeouts prevent cascading failures
- Graceful Degradation: Fallbacks at every layer (cache → retrieval → generation)
- Observability-First: Traces and metrics built into every code path
- Cost Awareness: Semantic caching reduces LLM spend by ~40-60%
When traffic spikes, the retriever scales out (2→30 replicas). When traffic drops, KServe scales the LLM to zero. When Weaviate slows down, OpenSearch takes over. When the LLM fails, deterministic fallbacks keep users informed.
Every point of failure has a fallback, to provide a resilient and good experience to users.
The complete code is available at github.com/aboullaite/rag-java-k8s.
Stay tuned for the last part, providing a Kubernetes deep dive.