
Git has quickly become an incredibly popular version control system, but how does it actually work? It's very different from a centralized version control system, and understanding how it models history allows you to understand how to use it.
This post tries to explain how Git actually works under the hood and how this makes Git fast and flexible.

.git: Where the magic happens
When you run git init in a new or existing directory, Git creates the .git directory, which is where almost everything that Git stores and manipulates is located. If you want to backup or clone your repository, copying this single directory elsewhere gives you nearly everything you need. This blog basically deals with the stuff in this directory. Here’s what it looks like:
$ ls -F1
HEAD
config*
description
hooks/
info/
objects/
refs/
This is a fresh git init repository. The description file is only used by the GitWeb program ( to display the description of the repo on the GitWeb page), so don’t worry about it. The config file contains your project specific configuration options, and the info directory keeps a global exclude file for ignored patterns that you don’t want to track in a .gitignore file. The hooks directory contains your client- or server-side hook scripts. This leaves four important entries: the HEAD and (yet to be created) index files, and the objects and refs directories. These are the core parts of Git.
The objects directory stores all the content for your database, the refs directory stores pointers into commit objects in that data (branches), the HEAD file points to the branch you currently have checked out, and the index file is where Git stores your staging area information.
Objects
A git repository is actually just a collection of objects, each identified with their own hash. Whenever you add a file, you get a hash generated on its contents, and this hash is used to uniquely point to that version of a file. For example, if you create an empty file, it will have the hash e69de29bb2d1d6434b8b29ae775ad8c2e48c5391. You can confirm this by adding an empty file to a repository and using git ls-tree to see the contents:
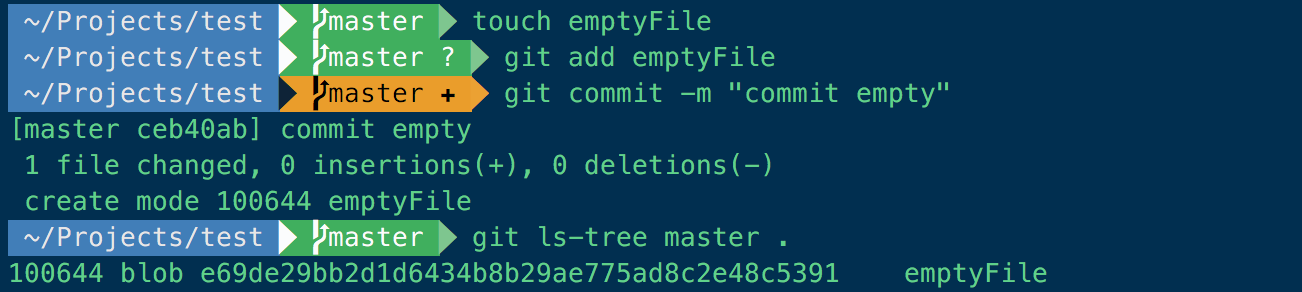
What git ls-tree is saying is that the master branch contains a file called emptyFile whose permissions are 100644 (owner read/write, groupe other read), and whose hash is e69de29bb2d1d6434b8b29ae775ad8c2e48c5391.
So, how does Git compute this value? Well, it uses SHA1 hash; but the SHA1 of an empty input isn't this value. In fact, Git prefixes the object with "blob ", followed by the length (as a human-readable integer), followed by a NUL character, followed by the contents. So for our case, we have:

It prints out the same value, e69de29bb2d1d6434b8b29ae775ad8c2e48c5391. Also, and instead of calculating this format ourselves, we can use git hash-object to calculate a hash – or, with -w, insert an object in our local repository:

But how Git organises objects into directories?!
Git uses a uniform storage model for all of its objects. Each object is identified with its hash, but the type of the object is stored in metadata along with the object. Thus, it's possible to find out from an ID what its type is, as well as its content using the -t option with git cat file command:

Technically, Git stores content in a manner similar to a UNIX filesystem, but a bit simplified. All the content is stored as tree and blob objects, with trees corresponding to UNIX directory entries and blobs corresponding more or less to inodes or file contents. A single tree object contains one or more tree entries, each of which contains a SHA-1 pointer to a blob or subtree with its associated mode, type, and filename.
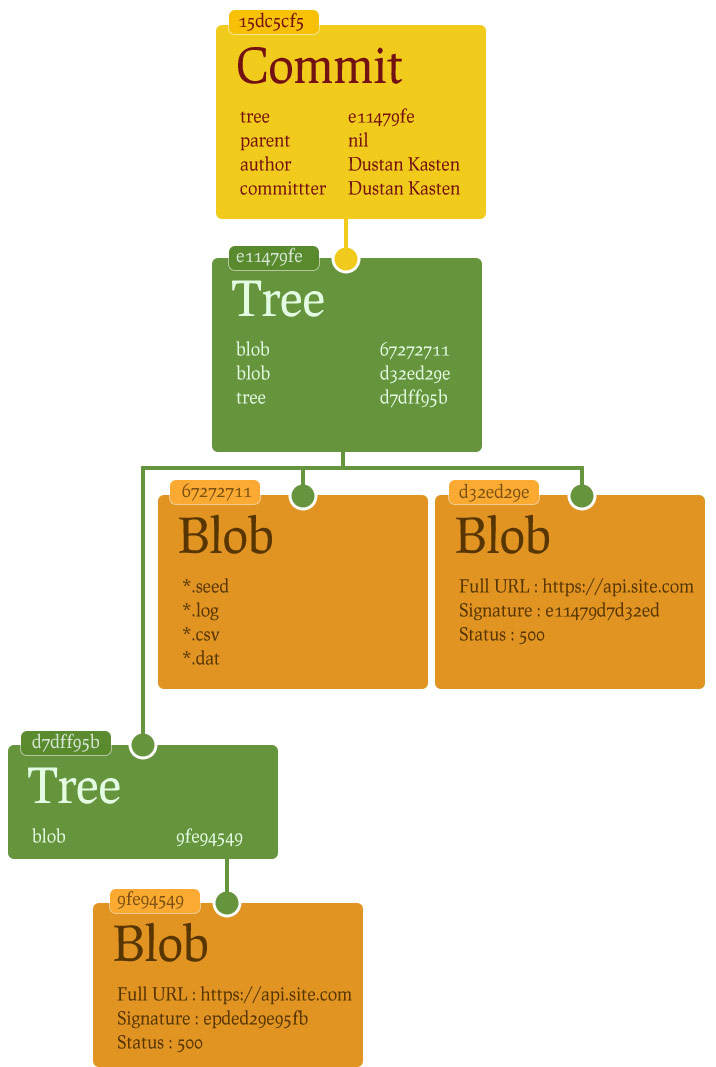
How is this tree created? Well, again, it's a well-formatted object which is hashed through its sha1 value. The object type is tree, and instead of having simple values like the blob, the tree is a set of index values pointing to the objects, along with a mode (typically 100644 for files and 100755 for directories). However, we know the size of the SHA hash, so it doesn't need to be in human-readable numbers; For example, the most recent tree in a project may look something like this:

Additionally, we can use the write-tree command to write the staging area out to a tree object:

Commit objects
It's not going to come as a surprise that a commit is a hashed object, stored in exactly the same mechanisms as blobs and trees are. A commit is a hash of the commit message, with an identifying type and length (as for blobs and trees).
To create a commit object, we simply call commit-tree and specify a single tree SHA-1 and which commit objects, if any, directly preceded it. Let's use our newly created tree:

The format for a commit object is simple: it specifies the top-level tree for the snapshot of the project at that point; the author/committer information (which uses your user.name and user.email configuration settings and a timestamp); a blank line, and then the commit message.
and Voila! next time we will talk about refs.
Credit:
- git image: https://dribbble.com/shots/1183331-Git-Love-Sticker
- git objects diagram: http://aht.github.io/whatisgit